MSSQL
Microsoft Structured Query Language
Temporäre Tabellen
Mittels DECLARE können nicht nur Variabeln sondern sogar ganze Tabellen definiert werden.
Folgende Tabelle werden für die Beispiele auf dieser Seite verwendet und können so erstellt werden:
DECLARE @items table
(
Name nvarchar(128) not null unique,
CategoryID int,
RatingID int
)
Beispieltabelle: Items
| Name | CategoryID | RatingID |
|---|---|---|
| Gummibärchen | 1 | 1 |
| Pommes Chips | 1 | 1 |
| Apfel | 2 | null |
| Kiwi | 2 | 1 |
| Banane | 2 | 2 |
| Curry | null | 3 |
| Essig | null | null |
Beispieltabelle: Categories
| ID | Name | GroupID |
|---|---|---|
| 1 | ungesund | 1 |
| 2 | gesund | 2 |
| 3 | giftig | null |
Beispieltabelle: Ratings
| ID | Description |
|---|---|
| 1 | habe ich gern |
| 2 | habe ich nicht gern |
| 3 | habe ich noch nie probiert |
Beispieltabelle: Groups
| ID | Description |
|---|---|
| 1 | essbar |
| 2 | spuckbar |
| 3 | würgbar |
Tabellen vereinen
Mit JOIN kann die ursprüngliche Tabelle von FROM mit einer zweiten Tabelle verbunden werden.
Die Verbindung selbst wird mit ON definiert.
(INNER) JOIN
Im Standard werden nur Zeilen ausgegeben, wo die Verbindung hergestellt werden konnte.
FROM Items i
JOIN Categories c ON i.CategoryID = c.ID
Das Ergebniss beinhaltet also weder die Kategorie "giftig" noch die Gegenstände "Curry" und "Essig".
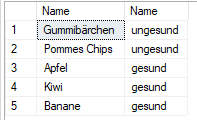
LEFT (OUTER) JOIN
Hier werden alle Zeilen aus der bestehenden Tabelle ausgegeben und, wenn vorhanden, mit der zweiten Tabelle ergänzt.
FROM Items i
LEFT JOIN Categories c ON i.CategoryID = c.ID
"Curry" und "Essig" werden also trotzdem angezeigt, einfach ohne die Werte aus der Kategorie-Tabelle. Jedoch die Kategorie "giftig" wird nicht angezeigt.
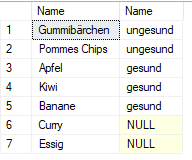
RIGHT (OUTER) JOIN
Hier werden alle Zeilen aus der zweiten Tabelle ausgegeben und, wenn vorhanden, mit der bestehenden Tabelle ergänzt.
FROM Items i
RIGHT JOIN Categories c ON i.CategoryID = c.ID
Im Ergebniss findet man die Kategorie "giftig", jedoch ohne einen Gegenstand, während "Curry" und "Essig" fehlen.
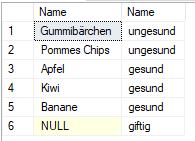
FULL (OUTER) JOIN
Damit werden alle Zeilen aus beiden Tabellen ausgegeben.
FROM Items i
FULL JOIN Categories c ON i.CategoryID = c.ID
Das Ergebniss beinhaltet alle Zeilen und wo vorhanden, auch mit den Infos der jeweils anderen Tabelle befüllt.
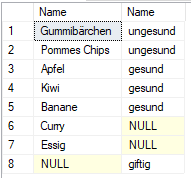
Mehrfach
Wenn mehrere Joins angewendet werden, dann ist die Reihenfolge, der verbundenen Tabelle relevant. Es gilt bei jedem Join wieder: linke Tabelle = aktuelle Tabelle, rechte Tabelle = neue Tabelle.
FROM Items i
LEFT JOIN Categories c ON i.CategoryID = c.ID
LEFT JOIN Groups g ON c.GroupID = g.ID
LEFT JOIN Ratings r ON i.RatingID = r.ID
Hier werden zuerst die Kategorien verbunden. Dann werden die Gruppen geladen und am Ende noch die Bewertungen.
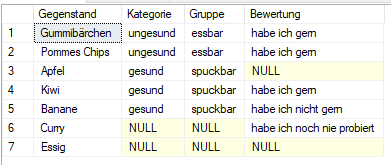
FROM Items i
LEFT JOIN Categories c ON i.CategoryID = c.ID
RIGHT JOIN Groups g ON c.GroupID = g.ID
FULL JOIN Ratings r ON i.RatingID = r.ID
In diesem Beispiel werden zuerst zu allen Gegenständen die Kategorie geladen.
Da dies mit LEFT JOIN geschieht, werden auch "Curry" und "Essig" mit der Kategorie "null" ausgegeben.
Danach wird mit RIGHT JOIN die Gruppe dazugeholt.
Deshalb entfallen hier "Curry" und "Essig" wieder, da ihre Kategorie "null" ist und folgend auch die Gruppe "null" ist.
Dafür kommt eine Zeile für die Gruppe "würgbar" dazu, welche weder einen Gegenstand noch eine Kategorie hat.
Im letzten Schritt kommt die Tabelle Bewertung anhand FULL JOIN dazu und bringt eine neue Zeile mit "habe ich noch nie probiert", welche alle restlichen Felder leer lässt.
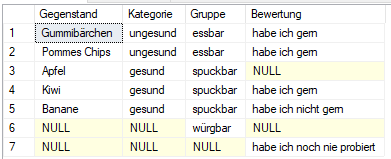
FROM Items i
FULL JOIN Ratings r ON i.RatingID = r.ID
LEFT JOIN Categories c ON i.CategoryID = c.ID
RIGHT JOIN Groups g ON c.GroupID = g.ID
In diesem Beispiel laden wir die Bewertung vor der Kategorie und der Gruppe.
Dies verdeutlicht, dass die Reihenfolge relevant ist.
Zuerst werden die Gegenstände mit der Bewertung anhand eines FULL JOIN geladen.
"Apfel" und "Essig" haben keine Bewertung und werden mit "null" dazugeladen.
Von den Bewertungen werden alle drei Stück verwendet, weshalb es keine weitere Zeile gibt.
Nun wird mit einem LEFT JOIN die Kategorie dazugeholt, welche die Anzahl der Zeilen unverändert lässt.
"Curry" und "Essig" bleiben mit einer "null" darin bestehen.
Mit einem RIGHT JOIN wird nun die Gruppe geladen.
Da "Curry" und "Essig" keine Gruppe besitzen, fallen sie weg.
Dafür wird die nicht verwendete Gruppe "würgbar" hinzugefügt.
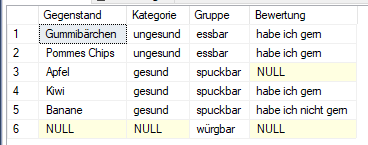
Blättern
Möchte man nur die ersten 10 Zeilen der Abfrage ausgegeben erhalten, kann dies einfach mit einem TOP 10 geschehen:
SELECT TOP 10 * FROM table ORDER BY name
Möchte man jedoch eine Funktion zum Blättern, ist das schon umständlicher. Dafür muss man dies nicht ganz so intuitiv am Ende der Abfrage hinzufügen:
SELECT *
FROM table
ORDER BY name
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY
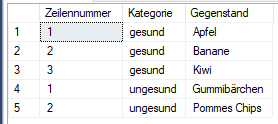
Nummerieren
Mittels ROW_NUMBER() können die Datensätze nummeriert werden.
Dies könnte nützlich sein um ID's zu generieren, wenn keine numerischen existieren, aber benötigt werden.
Oder auch um mittels einer Schleife die Ergebnisse weiter zu verarbeiten.
SELECT
Die Partition ist freiwillig und definiert eine Unterkategorie.
Sortiert werden muss immer.
ROW_NUMBER() OVER (PARTITION BY c.Name ORDER BY i.Name) as Zeilennummer,
c.Name as Kategorie,
i.Name as Gegenstand
FROM Items i
JOIN Categories c ON i.CategoryID = c.ID
Aggregieren
Im SQL kann man in mit GROUP BY-gruppierten Tabellen die Werte aggregieren.
Meistens nutzt man dafür SUM(Feldname) für die Summe.
Man kann mit COUNT(Feldname) die Anzahl ausgeben.
Möchte man einfach nur die Anzahl Zeilen auswerten geht dies auch mit COUNT(*).
Und man kann auch nur einmalige Werte zählen mit COUNT(DISTINCT Feldname).
Es kann sogar noch komplexer werden, wenn man bspw. leere Textfelder nicht mitzählen möchte mit einem CASE wie COUNT(DISTINCT CASE WHEN Feldname != '' THEN Feldname END).
Schleifen
Man kann im SQL mittels WHILE Schleifen nutzen.
Selbstverständlich kann man in der WHILE-Bedinung alle gültigen Vergleiche anstellen.
Das folgende Beispiel zeigt, wie man auch eine FOR-Schleife bauen kann.
Den nächsten Schleifendurchlauf lässt sich mittels CONTINUE einleiten.
DECLARE @i int = 0
WHILE @i < 10
BEGIN
SET @i = @i + 1
IF @i = 6 CONTINUE
PRINT CONCAT(@i, '. Iteration')
END

Json
MSSQL kann auch mit Json umgehen.
Ein Json-Objekt kann mit OPENJSON gelesen werden.
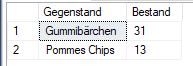
DECLARE @json nvarchar(max) = '[{"Gegenstand": "Gummibärchen", "Bestand": 31},{"Gegenstand": "Pommes Chips", "Bestand": 13}]'
SELECT * FROM OPENJSON(@json) WITH
(
Gegenstand nvarchar(max) 'strict $.Gegenstand',
Bestand int 'strict $.Bestand'
)
XML
Auch lässt sich mittels OPENXML dieses alte Format lesen.
Man kann mehrere Zeilen auslesen, wie auch Felderinhalte, -Bezeichnungen und -Attribute.
DECLARE @xml nvarchar(max) = '<gegenstaende><gegenstand order="1" added="20240204"><name>Apfel</name><bestand>7</bestand></gegenstand><gegenstand order="2"><name>Banane</name><bestand>3</bestand></gegenstand></gegenstaende>'
DECLARE @i int
EXEC sp_xml_preparedocument @i out, @xml, '<row xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" />'
SELECT * FROM OPENXML(@i, '/gegenstaende/*', 1) WITH
(
Gegenstand nvarchar(8) 'name',
Bestand int 'bestand',
Feld nvarchar(16) '@mp:localname',
Inhalt nvarchar(16) '.',
Reihenfolge int '@order'
)
EXEC sp_xml_removedocument @i

XQuery
Mit XQuery lassen sich noch einfacher XML-Daten verarbeiten.
DECLARE @essen table (Daten xml)
INSERT INTO @essen VALUES
('<essen id="1"><name>Gummibärchen</name><kategorie>ungesund</kategorie><gruppe>essbar</gruppe><bewertung>habe ich gern</bewertung></essen>'),
('<essen id="2"><name>Kiwi </name><kategorie>gesund</kategorie><gruppe>spuckbar</gruppe><bewertung>habe ich gern</bewertung></essen>'),
('<essen id="3"><name>Rattengift</name><kategorie>giftig</kategorie><gruppe>würgbar</gruppe><bewertung>habe ich noch nie probiert</bewertung></essen>')
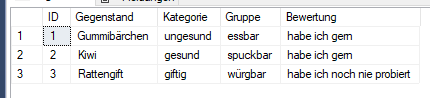
SELECT
Daten.value('(essen/@id)[1]', 'int') as ID,
Daten.value('(essen/name)[1]', 'nvarchar(16)') as Gegenstand,
Daten.value('(essen/kategorie)[1]', 'nvarchar(16)') as Kategorie,
Daten.value('(essen/gruppe)[1]', 'nvarchar(16)') as Gruppe,
Daten.value('(essen/bewertung)[1]', 'nvarchar(32)') as Bewertung
FROM @essen
Mit gegenstand[@order="1"]/@added kann man gezielt eine Node nach einem Attribut selektieren und darin ein anderes Attribut ausgeben lassen.
Hier wäre das Resultat 20240204.
Index
Ein Index ist eine interne "Merkliste" der Datenbank, um schneller den entsprechenden Datensatz im Speicher zu finden. Werden Datensätze entfernt und hinzugefügt, wird der entsprechende Index-Eintrag ebenfalls gelöscht bzw. hinzugefügt. Je öfters dies stattfindet, desto schneller fragmentiert der Index. Mit diesem Skript, lässt sich die Fragmentierung auslesen und optimieren, in dem er neu erstellt wird.
BEGIN TRANSACTION
DECLARE @overview as table
(
[Row] int,
[Schema] nvarchar(128),
[Table] nvarchar(128),
[Index] nvarchar(128),
[Fragmentation] float
)
INSERT INTO @overview
SELECT
ROW_NUMBER() OVER (ORDER BY d.avg_fragmentation_in_percent),
s.name as [Schema],
t.name as [Table],
i.name as [Index],
d.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS d
JOIN sys.tables t on T.object_id = d.object_id
JOIN sys.schemas s on T.schema_id = s.schema_id
JOIN sys.indexes i ON I.object_id = d.object_id AND d.index_id = i.index_id
WHERE d.database_id = DB_ID()
AND i.name IS NOT NULL
AND d.avg_fragmentation_in_percent > 0
DECLARE @i int = 0
DECLARE @max int = (SELECT MAX([row]) FROM @overview)
DECLARE @sql nvarchar(max)
WHILE @i < @max
BEGIN
SET @i = @i + 1
SET @sql =
(
SELECT CONCAT('ALTER INDEX [', [Index], '] ON ', [Table], ' REBUILD')
FROM @overview WHERE [row] = @i
)
EXEC(@sql)
END
--SELECT * FROM @overview ORDER BY [Row]
COMMIT TRANSACTION